Authentik's Blueprint Race Condition in Kubernetes
We run Authentik as our SSO provider across multiple Kubernetes clusters. To manage configuration declaratively, we store blueprints in ConfigMaps and mount them into the worker pod. This works great until you have blueprints that reference each other—then you hit a race condition that can silently break your entire auth setup.
This post covers the problem, our production workaround using a sidecar container, and what we think upstream Authentik could change to make ConfigMap-based blueprint management reliable.
The Problem: Parallel Blueprint Loading
Authentik's blueprint system discovers YAML files on disk and applies them. The discovery function (blueprints_discovery()) finds all .yaml files under /blueprints/ and enqueues each one as a separate async task via Dramatiq:
# From authentik/blueprints/v1/tasks.py
def check_blueprint_v1_file(path: Path):
# ... hash check ...
apply_blueprint.send_with_options(
args=(instance.pk,),
rel_obj=instance
)Every blueprint file becomes an independent async task. There is no ordering, no dependency resolution, no waiting for one to finish before starting the next.
Why This Matters
Blueprints can reference resources defined in other blueprints using !Find:
# 10-sources.yaml - depends on flows from 09-flows.yaml
- model: authentik_sources_oauth.oauthsource
attrs:
authentication_flow: !Find [authentik_flows.flow, [slug, ii-source-authentication-flow]]
enrollment_flow: !Find [authentik_flows.flow, [slug, ii-source-enrollment-flow]]If 10-sources.yaml applies before 09-flows.yaml, the !Find references resolve to None. The blueprint still reports "successful"—it just silently sets the flow fields to null.
The Dependency Chain
In our setup, the dependency graph looks like:
05-groups.yaml (no dependencies)
08-property-mappings (no dependencies)
09-flows.yaml (depends on: groups, property-mappings, stages)
10-sources.yaml (depends on: flows)
22-brand.yaml (depends on: flows)
30-providers.yaml (depends on: flows, sources)Files are named with numeric prefixes to suggest ordering, but blueprints_discovery() ignores this—it fires all tasks concurrently regardless of filename.
Why Not Just Re-run Discovery?
Your first instinct might be: call discovery twice. The second pass would find all dependencies already created.
This doesn't work. Authentik stores a SHA-512 hash of each blueprint file in PostgreSQL (BlueprintInstance.last_applied_hash). On subsequent discovery runs, it compares the file hash against the stored hash—if they match, the file is skipped entirely.
# The hash check that prevents re-application
if instance.last_applied_hash == file_hash:
# Skip - already applied
returnSo calling discovery twice does nothing. The blueprints were "successfully" applied (with null references), their hashes are stored, and they won't be touched again.
The Bypass: inotify File Events
There is one path that bypasses the hash check. Authentik runs a watchdog file watcher on the blueprints directory. When a file is modified (not just created), the on_modified handler fires:
class BlueprintEventHandler(FileSystemEventHandler):
def on_modified(self, event: FileSystemEvent):
path = Path(event.src_path)
root = Path(CONFIG.get("blueprints_dir")).absolute()
rel_path = str(path.relative_to(root))
for instance in BlueprintInstance.objects.filter(path=rel_path, enabled=True):
# Direct apply - NO hash check!
apply_blueprint.send_with_options(args=(instance.pk,), rel_obj=instance)This handler looks up the BlueprintInstance by relative path and directly enqueues apply_blueprint—no hash comparison. If we can trigger IN_MODIFY events on the blueprint files after the initial discovery completes, each blueprint gets unconditionally re-applied with all dependencies now present.
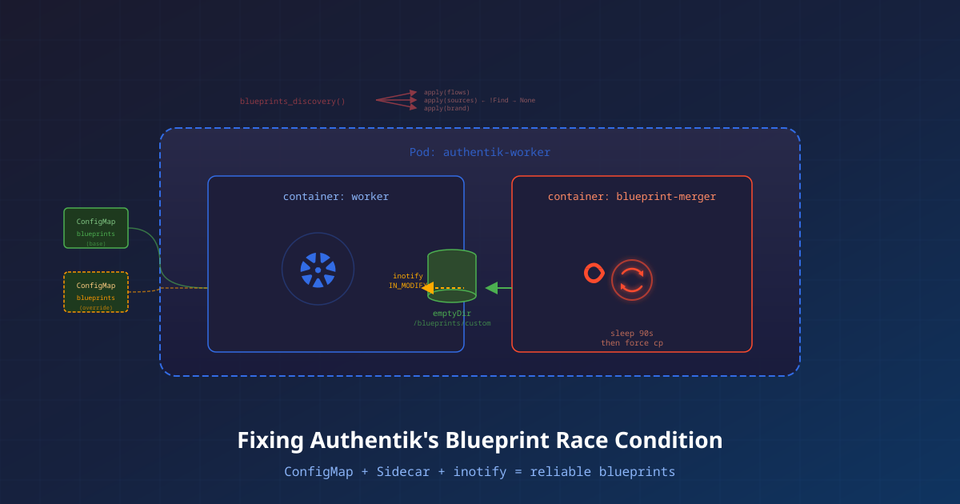
The Fix: A Blueprint Merger Sidecar
We deploy a busybox sidecar in the worker pod that:
- Shares the same
emptyDirvolume as the worker (/blueprints/custom) - Waits for the initial discovery to settle (90 seconds)
- Force re-copies all blueprint files, triggering
IN_MODIFYinotify events - Continuously watches for ConfigMap changes and merges them
Architecture
Pod: authentik-worker
├─ initContainer: copy-blueprints
│ Copies ConfigMap files → emptyDir (guarantees files exist before worker boots)
│
├─ container: worker
│ Runs blueprints_discovery() on boot (concurrent, race-prone)
│ Runs watchdog file watcher on /blueprints/ (handles re-apply)
│ Mounts emptyDir at /blueprints/custom
│
└─ container: blueprint-merger (sidecar)
Phase 1: sleep 90s (let discovery finish)
Phase 2: force re-copy from ConfigMaps → emptyDir (triggers inotify)
Phase 3: poll for ConfigMap changes every 30s (hot reload)
Mounts emptyDir at /outputTwo ConfigMaps: Config + Override
We split blueprint management into two ConfigMaps:
| ConfigMap | Source | Purpose |
|---|---|---|
authentik-blueprints | Nix/GitOps | Base blueprints, source of truth |
authentik-blueprints-override | kubectl edit | Runtime overrides, same-name wins |
The sidecar merges both (override wins on filename collision) before writing to the emptyDir. This gives you:
- GitOps for base config—blueprints managed in version control
- Hot reload without restarts—edit the override ConfigMap, sidecar picks it up within 30s
- Clean separation—override ConfigMap is optional (marked
optional: true)
The Sidecar Script
POLL_INTERVAL=30
merge_blueprints() {
changed=0
for f in /config/base/*.yaml; do
[ -f "$f" ] || continue
name=$(basename "$f")
[ -f "/config/override/$name" ] && continue
if ! cmp -s "$f" "/output/$name" 2>/dev/null; then
cp "$f" "/output/$name"
changed=$((changed + 1))
fi
done
if [ -d /config/override ]; then
for f in /config/override/*.yaml; do
[ -f "$f" ] || continue
name=$(basename "$f")
if ! cmp -s "$f" "/output/$name" 2>/dev/null; then
cp "$f" "/output/$name"
changed=$((changed + 1))
fi
done
fi
echo "$changed"
}
echo "[blueprint-merger] Waiting for initial discovery to settle..."
sleep 90
echo "[blueprint-merger] Force re-copy to trigger inotify re-apply..."
for f in /config/base/*.yaml; do
[ -f "$f" ] || continue
name=$(basename "$f")
src="$f"
[ -f "/config/override/$name" ] && src="/config/override/$name"
cp "$src" "/output/$name"
done
echo "[blueprint-merger] Race condition fix applied"
echo "[blueprint-merger] Watching for changes (${POLL_INTERVAL}s)..."
while true; do
sleep "$POLL_INTERVAL"
changed=$(merge_blueprints)
[ "$changed" != "0" ] && echo "[blueprint-merger] Updated $changed blueprint(s)"
doneWhy This Works
The key insight: cp file dest where dest already exists opens the file for writing and writes new data. This generates an IN_MODIFY inotify event. The worker's watchdog watcher catches this and calls apply_blueprint directly—no hash check, no discovery, just a straight re-apply.
By the time the sidecar fires (T+90s), all blueprints have been applied at least once. The dependency resources exist in the database. When the re-apply runs, every !Find reference resolves correctly.
apply_blueprint tasks firing at exactly T+90s after boot. All 8 custom blueprints report "successful" with correct cross-references. OAuth sources have their flows properly bound.Why Not a postStart Lifecycle Hook?
We tried this first—a lifecycle.postStart hook on the worker container that re-copies files after a delay:
lifecycle:
postStart:
exec:
command: ["sh", "-c", "(sleep 60 && cp /source/*.yaml /blueprints/custom/) &"]This works in principle, but has downsides:
- No ongoing watch—only fires once at startup, doesn't handle ConfigMap updates
- No override merging—can only copy from one source
- Background process in main container—harder to monitor, logs mixed with worker output
- Fixed delay—if discovery takes longer than expected, the fix might fire too early
The sidecar is cleaner: dedicated container, separate logs, persistent watch loop, and merge capability.
Suggested Upstream Changes
The sidecar works, but it's a workaround for what should be handled in Authentik itself. Here are three approaches the upstream project could consider:
Option A: Two-Pass Discovery (Minimal Change)
After the initial concurrent application, run a second pass that re-applies only blueprints with !Find references. The hash check already prevents redundant work on blueprints without cross-references:
def blueprints_discovery():
blueprints = blueprints_find()
# First pass: apply all (concurrent, fast)
for bp in blueprints:
apply_blueprint.send_with_options(args=(bp.pk,))
# Second pass: re-apply those with !Find references
# Wait for first pass to complete, then:
for bp in blueprints_with_find_references():
instance = BlueprintInstance.objects.get(path=bp.path)
instance.last_applied_hash = "" # Clear hash to force re-apply
instance.save()
apply_blueprint.send_with_options(args=(instance.pk,))Option B: Dependency-Ordered Application
Parse !Find references before applying and build a dependency graph. Apply in topological order:
def blueprints_discovery_ordered():
blueprints = blueprints_find()
# Build dependency graph from !Find references
deps = build_dependency_graph(blueprints)
# Apply in topological order (no parallelism for dependent blueprints)
for level in topological_sort(deps):
# Apply all blueprints at this level concurrently
for bp in level:
apply_blueprint.send_with_options(args=(bp.pk,))
# Wait for this level to complete before next level
wait_for_tasks(level)Option C: Retry with Backoff on None References
The simplest behavioral fix: if a !Find resolves to None during apply, treat it as a retryable failure rather than silently accepting null:
class BlueprintFind:
def resolve(self, model, identifiers):
result = model.objects.filter(**identifiers).first()
if result is None:
raise BlueprintDependencyNotReady(
f"!Find [{model.__name__}, {identifiers}] resolved to None. "
"Referenced resource may not exist yet."
)
return resultCombined with Dramatiq's retry mechanism (which is currently dead code in the blueprint system), this would make the concurrent approach self-healing.
Deployment: Nix + Helm Values
For those using the Authentik Helm chart, here's what the relevant values look like (expressed as Nix, but the structure maps 1:1 to YAML Helm values):
# Volumes: emptyDir + two ConfigMaps
global.volumes = [
{ name = "blueprints-live"; emptyDir = {}; }
{ name = "blueprints-config"; configMap.name = "authentik-blueprints"; }
{ name = "blueprints-override"; configMap = {
name = "authentik-blueprints-override";
optional = true;
}; }
];
# Worker mounts emptyDir where the watcher monitors
global.volumeMounts = [
{ name = "blueprints-live"; mountPath = "/blueprints/custom"; }
];
# Init container: copy before worker boots
worker.initContainers = [{
name = "copy-blueprints";
image = "busybox:latest";
command = ["sh" "-c" "cp /source/*.yaml /blueprints/ 2>/dev/null; cp /override/*.yaml /blueprints/ 2>/dev/null; true"];
volumeMounts = [
{ name = "blueprints-config"; mountPath = "/source"; readOnly = true; }
{ name = "blueprints-override"; mountPath = "/override"; readOnly = true; }
{ name = "blueprints-live"; mountPath = "/blueprints"; }
];
}];
# Sidecar: race condition fix + hot reload
worker.extraContainers = [{
name = "blueprint-merger";
image = "busybox:latest";
command = ["sh" "-c" "... sidecar script ..."];
volumeMounts = [
{ name = "blueprints-config"; mountPath = "/config/base"; readOnly = true; }
{ name = "blueprints-override"; mountPath = "/config/override"; readOnly = true; }
{ name = "blueprints-live"; mountPath = "/output"; }
];
}];Key Takeaways
- Authentik blueprints with
!Findcross-references are not safe under concurrent application. The discovery system fires all apply tasks in parallel with no ordering guarantees. - The hash check prevents naive re-application. You can't just call discovery twice—it skips already-applied blueprints.
- The file watcher's
on_modifiedhandler bypasses the hash check. This is the key to triggering re-application. - A sidecar that writes to the shared emptyDir triggers inotify in the worker container. Containers in the same pod share filesystem state on emptyDir volumes.
- The two-ConfigMap pattern (config + override) enables both GitOps and runtime editing. Hot reload without pod restarts.
If you're managing Authentik blueprints via ConfigMaps in Kubernetes and your blueprints have cross-references, you'll hit this race condition on every fresh deployment. The sidecar pattern is a reliable workaround until upstream addresses the concurrent apply issue.